什么时候需要看这页
Provider Agent 会调用本机 Ollama 执行推理。启动 Provider Agent 前,需要先安装 Ollama,并把要提供的模型下载到本地。
安装 Ollama
打开 Ollama 下载页,按你的系统选择安装方式。
macOS 用户可以下载图形安装包。Ollama 下载页也提供终端安装命令:
curl -fsSL https://ollama.com/install.sh | shLinux 用户通常使用同一条终端安装命令。Windows 用户请在下载页选择 Windows 安装包并按安装向导完成安装。
安装后确认命令可用:
ollama --version如果提示找不到 ollama 命令,先重新打开终端;仍不可用时,检查 Ollama 是否安装成功,以及命令是否已加入系统 PATH。
启动 Ollama
macOS 和 Windows 安装桌面应用后,通常会自动启动 Ollama 后台服务。也可以手动启动:
ollama serve如果提示端口已被占用,通常表示 Ollama 已在后台运行,不需要重复启动。
下载模型
在 Ollama 模型库 中选择模型,记下模型名。下载命令是:
ollama pull <model_name>例如:
ollama pull qwen3.5:9b这里的 <model_name> 要和 Provider Agent 的 --model 保持一致。例如下载的是 qwen3.5:9b,启动 Provider Agent 时也应使用:
./token-provider-agent start --api-key stp-... --model qwen3.5:9b设置上下文窗口
Ollama 桌面版可以在 Settings 里设置全局 Context length。打开 Ollama 的设置页面,找到 Context length 滑块,按目标模型要求的上下文窗口设置;截图中设置到 128k 只是示例,实际值应参考你要提供的模型需求。
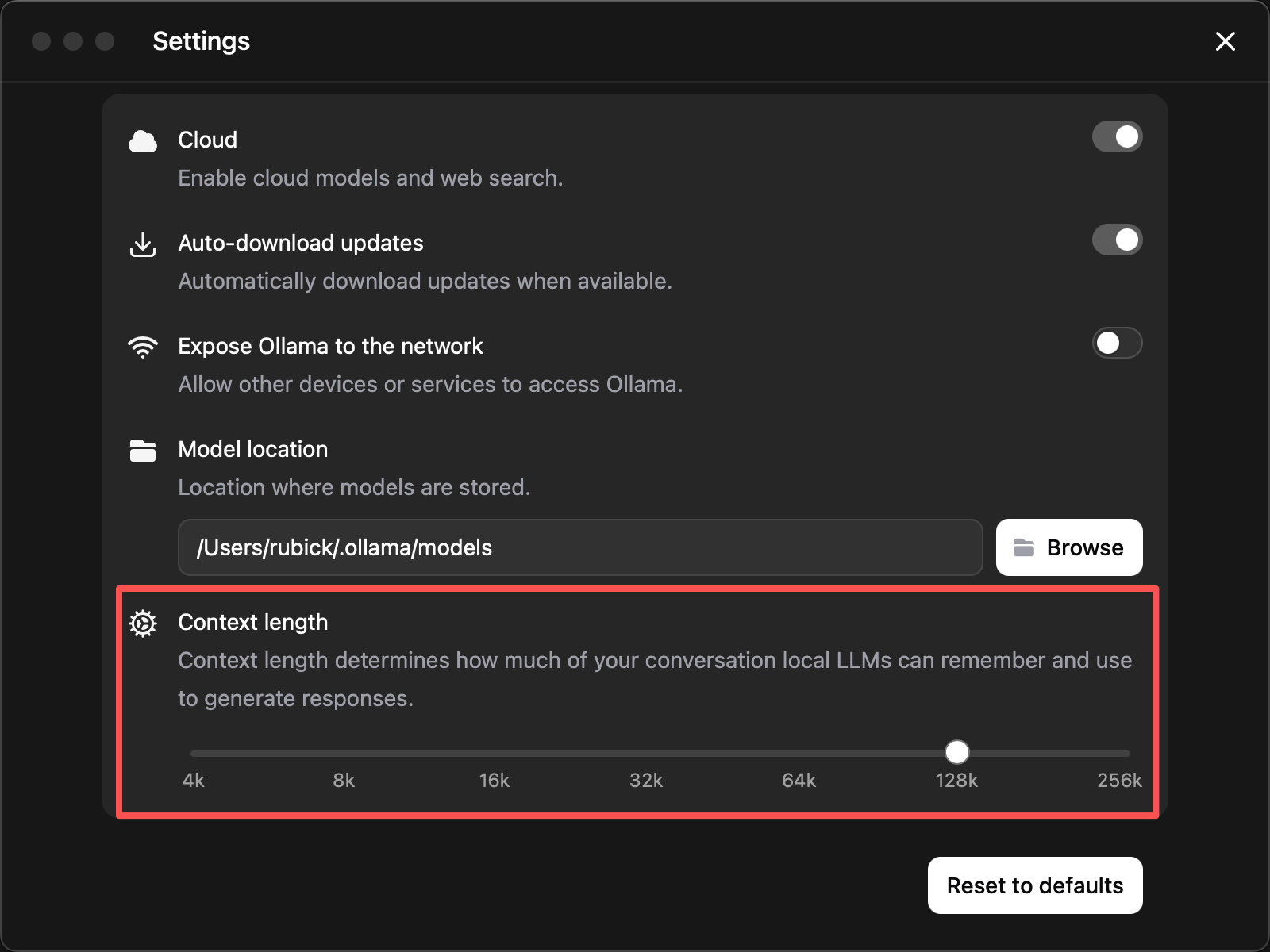
常见换算是:128K 对应 131072 tokens,256K 对应 262144 tokens。如果目标模型只要求 128K,就不要为了统一而设置到 256K;如果目标模型明确支持 256K,才设置到对应窗口。上下文窗口越大,KV cache 占用越高,机器内存或显存不足时可能导致加载失败、推理变慢或运行中断。
注意:
Context length是模型运行时可使用的上下文窗口- OpenAI 请求体里的
max_tokens只是本次最多生成多少 token,不是上下文窗口 - 模型本身必须支持你设置的目标上下文窗口,不能只靠 Ollama 设置突破模型上限
- 多个模型共用同一个 Ollama 全局设置时,以当前要承接 Provider 节点任务的模型需求为准
验证模型
查看本地模型列表:
ollama ls确认输出中包含你准备使用的模型名。
再做一次简单推理:
ollama run qwen3.5:9b "你好,请用一句话介绍你自己。"如果能正常返回文本,说明模型基本可用。
最后确认 Provider Agent 能访问同一个 Ollama 服务:
./token-provider-agent models --json如果 ollama ls 能看到模型,但 Provider Agent 看不到,优先检查 --base-url 或 PROVIDER_AGENT_BASE_URL 是否指向同一个 Ollama 地址。默认地址是 http://127.0.0.1:11434。
--ollama-base-url 和 PROVIDER_AGENT_OLLAMA_BASE_URL 仍被旧版本兼容,但新版本文档统一使用 --base-url / PROVIDER_AGENT_BASE_URL。