什么时候需要看这页
如果你希望用 LM Studio 桌面版承接 Provider 节点推理任务,先按这页在图形界面里下载模型、设置上下文长度,并启动 LM Studio 本地服务器。LM Studio 暴露的是 OpenAI-compatible 接口,Provider Agent 侧需要使用 --api-format lmstudio。
Token 供应示例里的模型名,例如 qwen3.6:35b、gemma4:26b,是启动 Provider Agent 时使用的平台模型代码。控制台会同时展示“模型名称”和“模型 ID”:模型名称用于在 LM Studio 或 Hugging Face 中搜索确认模型;模型 ID 是 LM Studio /v1/models 返回、Provider Agent 预检和真实请求使用的标识。
适用系统和特点
LM Studio 适合想用图形界面管理模型的本地 Provider。官方系统要求当前主要覆盖:
- macOS:Apple Silicon Mac,Intel Mac 当前不支持
- Windows:x64 和 ARM,x64 需要 AVX2
- Linux:x64 和 ARM64,以 AppImage 分发,官方要求 Ubuntu 20.04+
主要优点:
- 安装和下载模型都可以通过图形界面完成
- 支持 Hugging Face 搜索、GGUF 模型、Apple Silicon 上的 MLX 模型
- 内置 OpenAI-compatible
/v1/models、/v1/chat/completions等接口 - 默认本地运行,适合桌面或小型工作站
主要限制:
- 大模型和长上下文窗口非常依赖内存、显存和量化格式
- 官方没有提供完整的 NVIDIA、AMD、Intel GPU 兼容矩阵,实际性能需要按机器实测
- GUI 方便,但多机部署和批量运维不如 vLLM、SGLang 直接
- OpenAI-compatible 行为和云端 OpenAI 不会完全相同,复杂参数需要实测
安装 LM Studio
打开 LM Studio 下载页,按系统下载安装包。
安装后打开 LM Studio,确认可以进入 Chat、Discover、My Models 和 Developer 等页面。如果这是第一次安装,建议先在 Chat 页面加载一个小模型做一次试用,确认模型推理和显卡/内存配置正常。
后续下载模型、调整模型加载参数和启动本地推理服务,都会从左侧导航进入对应页面。如果找不到配置入口,先确认左侧导航栏里的模型管理、模型搜索和 Developer 入口;模型下载在 Discover/模型搜索页完成,推理服务与运行时上下文窗口在 Developer 的本地服务页面调整。
下载模型
进入 LM Studio 的 Discover 页面,在搜索框里输入模型关键词、完整 user/model 名称,或粘贴 Hugging Face 模型地址。
实际使用时,先打开 Provider API 密钥页,在 Token 供应示例中选择目标模型和 LM Studio 推理框架,然后分别点击“复制模型名称”和“复制模型 ID”。模型名称用于搜索、下载和加载模型;模型 ID 必须能在 LM Studio 的 /v1/models 中看到,也是 Provider Agent 的 --runtime-model-id / PROVIDER_AGENT_RUNTIME_MODEL_ID。
搜索时可以输入模型名称的一部分,但下载前必须在右侧模型详情顶部确认完整模型名称和复制出的模型名称一致,例如 qwen/qwen3.6-35b-a3b。不要只看列表里的显示名,也不要误选同名的社区 GGUF 变体;如果界面提供复制按钮,优先复制详情页里的完整模型名称再核对。
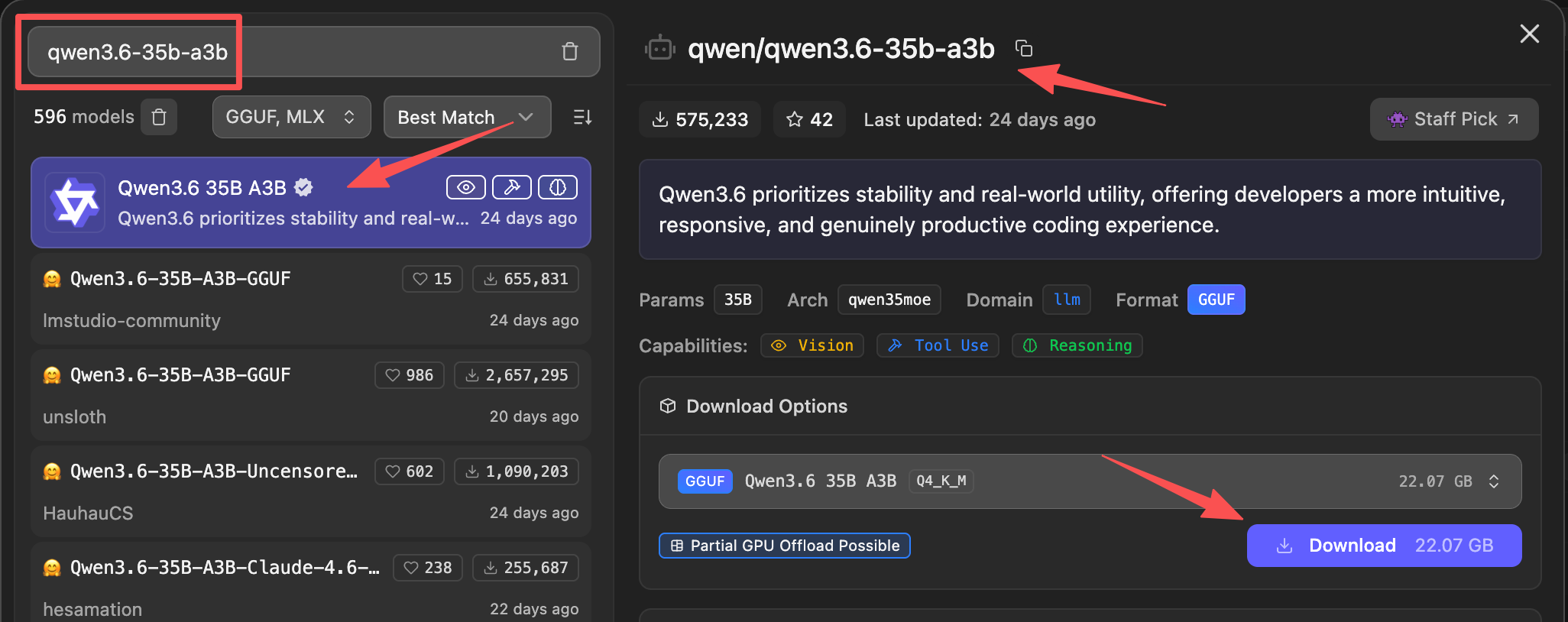
示例模型对应关系如下,最终以页面里“模型名称 / 模型 ID”显示的值,以及本地 /v1/models 实际返回为准:
| Token 供应示例模型名 | LM Studio 模型名称 | LM Studio 模型 ID | 说明 |
|---|---|---|---|
qwen3.6:35b | qwen/qwen3.6-35b-a3b | qwen/qwen3.6-35b-a3b | 以 LM Studio 模型库和实际下载结果为准 |
gemma4:26b | google/gemma-4-26b-a4b | google/gemma-4-26b-a4b | 以 LM Studio 模型库和实际下载结果为准 |
下载完成后,进入 My Models 页面确认模型已经出现在本机模型列表里。
设置上下文窗口
如果希望后续加载模型时长期使用固定上下文窗口,先在左下角进入 Settings,打开 Model Defaults,在 Default Context Length 里选择 Custom value,并填入目标模型要求的上下文窗口大小。这个设置会作为后续加载模型的默认值;如果模型实际支持的最大上下文更低,LM Studio 会按模型能力使用更低的值。
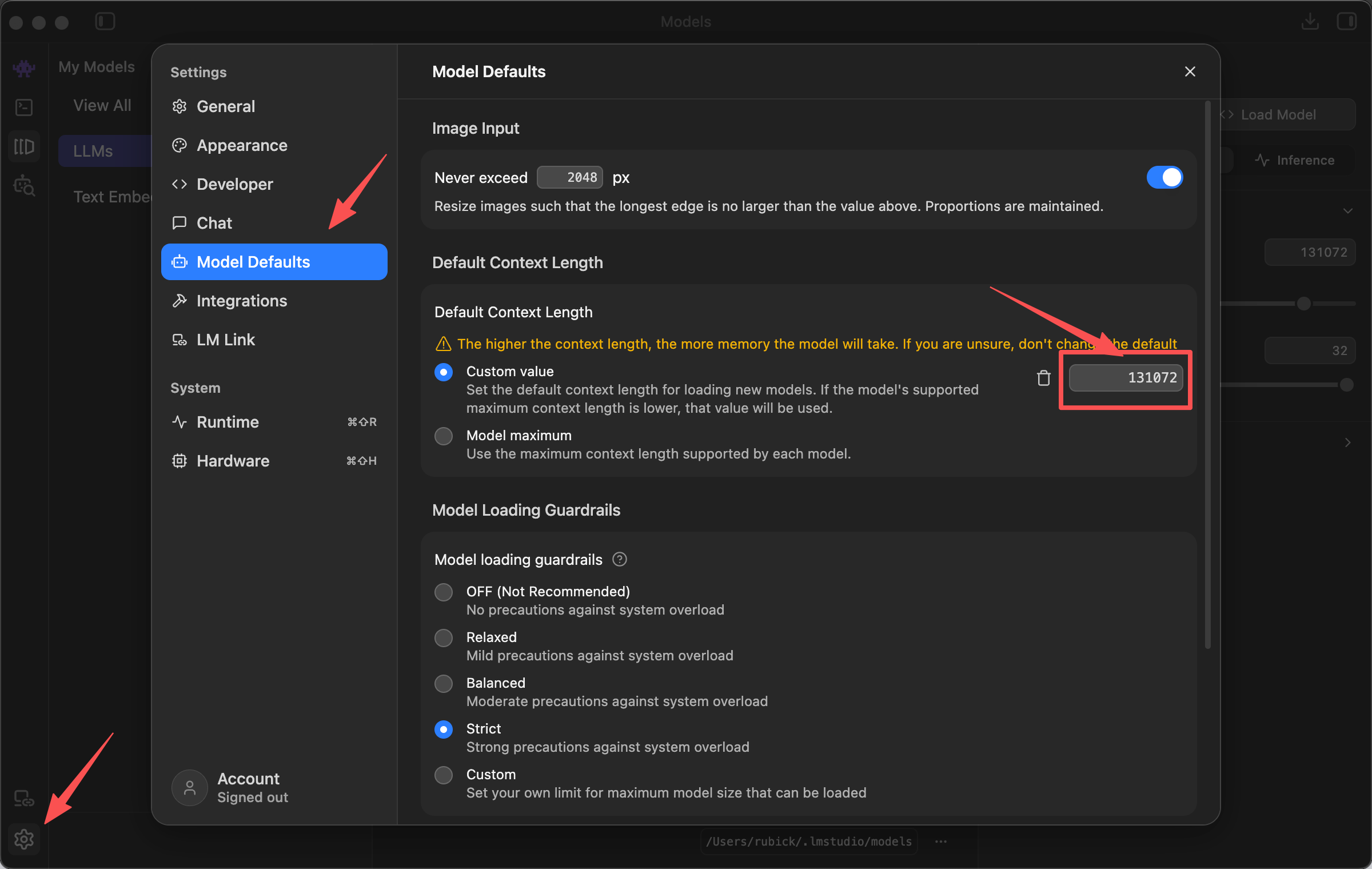
也可以给单个模型设置默认加载参数。进入 My Models 页面,点击目标模型旁边的齿轮按钮,在默认加载设置中把 Context Length 或 Context Size 设置为目标模型要求的“上下文窗口”大小。这个值不能默认所有模型都写成同一个数字,应以模型卡、实际下载模型和 LM Studio 展示的能力为准。
如果目标模型明确支持 256K 上下文窗口,可以设置为:
262144这表示 256K 上下文窗口。保存后,下次从 Chat 页面或 API 服务加载该模型时,会优先使用这个默认值。若目标模型要求 128K,则应设置为 131072;其他模型按对应要求填写。
也可以在加载模型前临时调整 Load Settings,把 Context Length 改成目标模型要求的 token 数,并按需调整 GPU Offload、Flash Attention 等选项。设置完成后再加载模型。
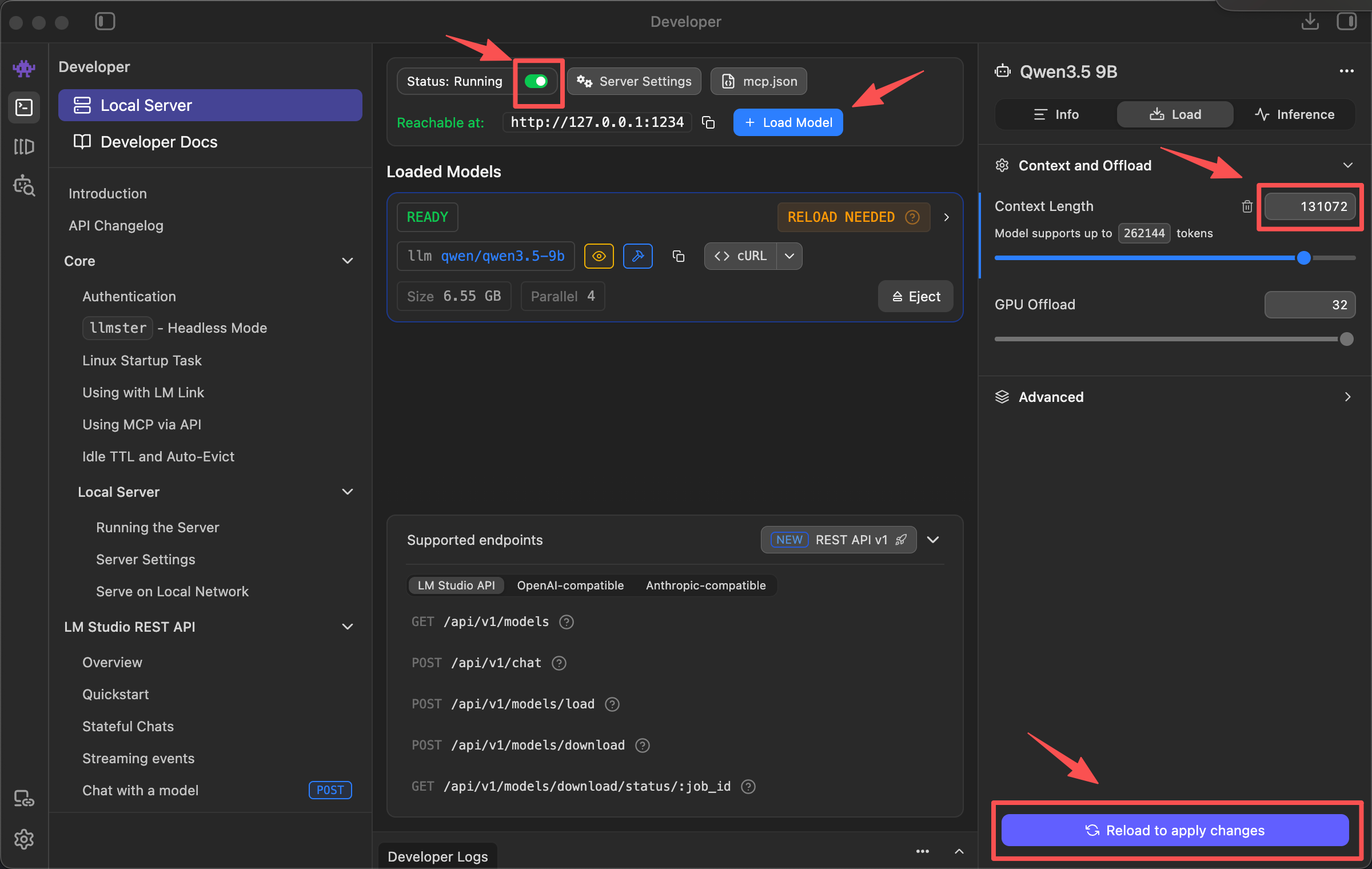
如果你在 Developer 页面直接为本地服务加载模型,也可以在右侧 Context and Offload 区域调整 Context Length。修改后如果页面提示需要重新加载,点击 Reload to apply changes,让新上下文窗口配置真正生效。
注意:
- Context Length 是加载模型时的上下文窗口
- OpenAI 请求体里的
max_tokens只是本次最多生成多少 token - 模型本身必须支持你设置的目标上下文窗口大小,上下文越大,KV cache 占用越高
加载模型
进入 Chat 页面,打开模型加载器,选择刚下载的模型。加载前确认 Load Settings 中的 Context Length 已经按目标模型要求设置,然后点击加载。
如果你要使用 gemma4:26b,同样选择 google/gemma-4-26b-a4b 对应的本地模型,并确认它的 Context Length 已按该模型要求设置。
加载完成后,可以先在 Chat 页面输入一句简单问题。如果能正常返回文本,说明模型已经在 LM Studio 内可用。
启动 OpenAI-compatible 服务
进入 Developer 页面,找到本地 API Server 区域,点击 Start server。LM Studio 官方文档说明,本地服务器可以从 Developer 页面启动,默认示例端口通常是 1234。
在 Server Settings 中确认:
- Server Port 是
1234,或记下你实际设置的端口 - 只在需要局域网访问时打开 Serve on Local Network
- 普通本机 Provider 节点可以先关闭 Require Authentication;如果打开,需要创建 API Token,并在 Provider Agent 中传入
--runtime-api-key
LM Studio 常用 base URL 是:
http://127.0.0.1:1234/v1默认情况下本地服务不要求 API Key。如果你在 Server Settings 中开启了 Require Authentication,请在请求和 Provider Agent 启动参数里使用对应 token。
服务启动正常时,Developer 页面会显示 Status: Running,Reachable at 会给出本地访问地址,目标模型卡片会显示 READY。此时再继续执行下面的 /v1/models 和 /v1/chat/completions 验证。
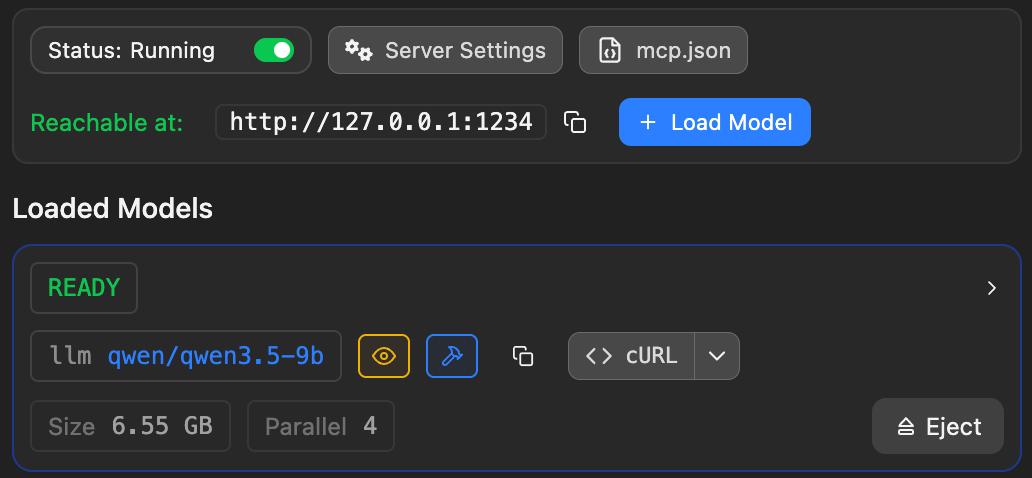
验证 LM Studio 服务
查看模型列表:
curl http://127.0.0.1:1234/v1/models做一次非流式推理。model 使用 /v1/models 里看到的实际 ID。按本页示例,通常应是 qwen/qwen3.6-35b-a3b:
curl http://127.0.0.1:1234/v1/chat/completions \ -H "Content-Type: application/json" \ --data-raw '{ "model": "qwen/qwen3.6-35b-a3b", "messages": [ { "role": "user", "content": "用一句中文回复:LM Studio 服务可用。" } ], "max_tokens": 64, "temperature": 0.2 }'如果启用了鉴权,增加:
-H "Authorization: Bearer <LMSTUDIO_TOKEN>"启动 Provider Agent
LM Studio 服务可用后,先跑预检:
./token-provider-agent preflight start \ --model qwen3.6:35b \ --base-url http://127.0.0.1:1234 \ --api-format lmstudio \ --runtime-model-id qwen/qwen3.6-35b-a3b预检通过后正式启动:
./token-provider-agent start \ --api-key stp-... \ --model qwen3.6:35b \ --base-url http://127.0.0.1:1234 \ --api-format lmstudio \ --runtime-model-id qwen/qwen3.6-35b-a3b如果 LM Studio 开启了 Require Authentication,同时传入:
--runtime-api-key <LMSTUDIO_TOKEN>命令行补充
LM Studio 也提供 lms 命令行工具,适合需要自动化脚本的高级用户。普通桌面用户不需要使用它;如果要排查模型标识,可以用 lms ls 查看本机模型列表,用 lms ps 查看已经加载到内存的模型。