什么时候需要看这页
如果你的 Provider 节点运行在 Apple Silicon Mac 上,并准备用 oMLX 承接推理任务,先按这页启动 oMLX 服务和模型实例。oMLX 暴露 OpenAI-compatible 接口,Provider Agent 侧需要使用 --api-format omlx。
这里的 oMLX 指面向 macOS 和 MLX 模型的推理服务器。Apple 官方 mlx_lm.server 也能提供类似 OpenAI Chat API 的本地 HTTP 服务,但它的生产能力和上下文窗口配置项不如 oMLX 明确;本页默认按 oMLX 流程说明。
适用系统和特点
oMLX 主要面向 Apple Silicon Mac。官方说明要求 Apple Silicon M1 或更新、macOS 15+,16GB 内存是最低门槛,64GB+ 更适合较大模型和长上下文。
主要优点:
- 原生面向 macOS 和 MLX,适合 Apple Silicon 统一内存机器
- 支持 OpenAI-compatible
/v1/chat/completions和 Anthropic-compatible/v1/messages - 支持多模型服务、菜单栏应用、Admin Dashboard 和模型管理
- 支持连续批处理和 SSD 分层 KV cache,适合 coding agent 这类重复前缀较多的场景
- 可以复用已有 LM Studio 模型目录,前提是模型格式适配
主要限制:
- 不适用于 Windows、Linux 服务器或 NVIDIA/AMD GPU 机器
- 需要 MLX 格式模型,不能直接把 Ollama 模型或普通 GGUF 当作 oMLX 模型目录使用
- oMLX 是第三方项目,不是 Apple 官方 MLX 项目
安装 oMLX
推荐从 oMLX 官网 下载 DMG,拖入 Applications 后启动。首次启动时,按欢迎界面选择模型目录、启动服务并下载模型。
也可以从源码安装:
git clone https://github.com/jundot/omlxcd omlxpip install -e .启动服务:
# 启动前先在 Admin Dashboard 或配置文件中按模型要求设置 max_context_windowomlx serve --model-dir ~/models默认服务地址是:
http://127.0.0.1:8000如果你的版本支持 Homebrew,也可以按项目 README 或 release 说明安装:
brew tap jundot/omlx https://github.com/jundot/omlxbrew install omlx准备模型
Token 供应示例里的模型名,例如 qwen3.6:35b、gemma4:26b,是启动 Provider Agent 时使用的平台模型代码。oMLX 运行时需要的是 MLX 格式模型、模型目录或模型 alias;控制台展示的“模型名称”用于搜索和下载模型,“模型 ID”用于 oMLX 对外暴露的 OpenAI-compatible 模型标识和 Provider Agent 的 --runtime-model-id。
实际使用时,先打开 Provider API 密钥页,在 Token 供应示例中选择目标模型和 oMLX 推理框架,然后分别点击“复制模型名称”和“复制模型 ID”。模型名称用于在 oMLX 或 Hugging Face 中搜索下载;模型 ID 是 /v1/models、验证请求里的 model,也是 Provider Agent 的 --runtime-model-id / PROVIDER_AGENT_RUNTIME_MODEL_ID。
然后打开 oMLX 控制台的 Models 页面,在 Search HuggingFace 搜索框里输入复制出的模型名称,保持 MLX only 过滤开启,点击 Search。搜索结果命中后,点击对应模型右侧的 Download 下载。截图里的 mlx-community/Qwen3.6-35B-A3B-4bit 只是操作方式示例;实际下载项必须以你复制出的模型名称、oMLX 搜索结果和 /v1/models 返回为准。
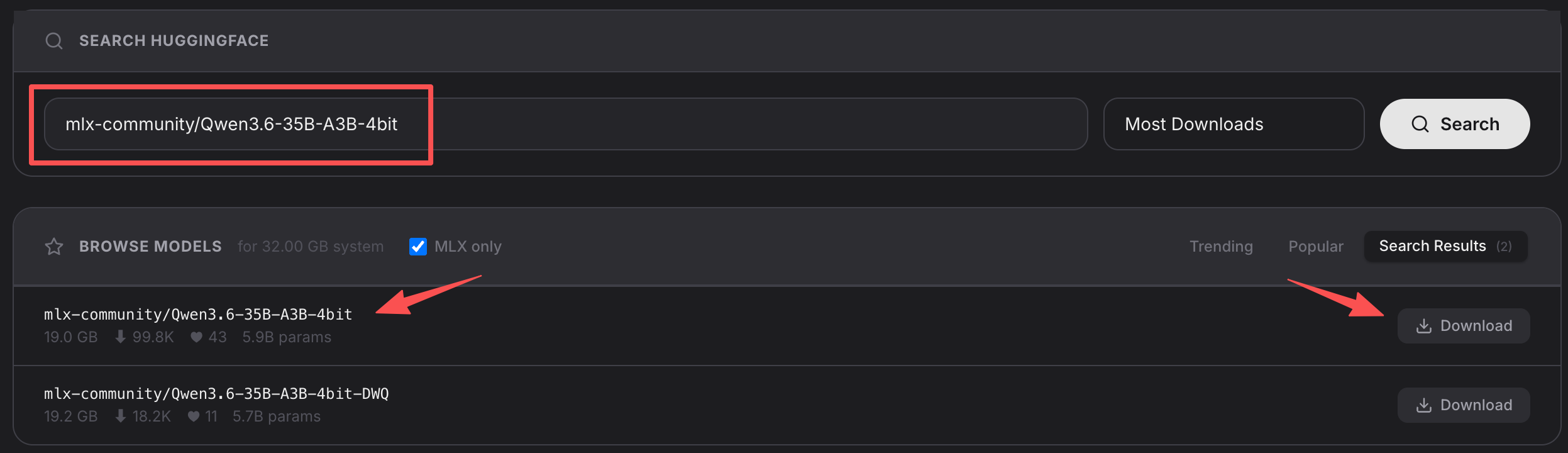
建议做法如下,最终以页面里“模型名称 / 模型 ID”显示的值为准:
| Token 供应示例模型名 | oMLX 模型名称 | oMLX 模型 ID | 说明 |
|---|---|---|---|
qwen3.6:35b | mlx-community/Qwen3.6-35B-A3B-4bit | Qwen3.6-35B-A3B-4bit | 以 oMLX Dashboard 和 /v1/models 实际返回为准 |
gemma4:26b | mlx-community/gemma-4-26b-a4b-it-4bit | gemma-4-26b-a4b-it-4bit | 以 oMLX Dashboard 和 /v1/models 实际返回为准 |
设置上下文窗口
oMLX 对应字段是 max_context_window。这个值应按目标模型要求设置,而不是所有模型固定写成同一个数字。常见换算是:128K 对应 131072 tokens,256K 对应 262144 tokens。
推荐在 oMLX Admin Dashboard 里进入 Settings,找到 Generation Defaults 区域里的 Max Context Window,按对应模型要求填写上下文长度。不同版本也可能支持在具体模型设置里覆盖上下文窗口;如果同时存在全局默认值和模型级设置,以模型级设置为准。
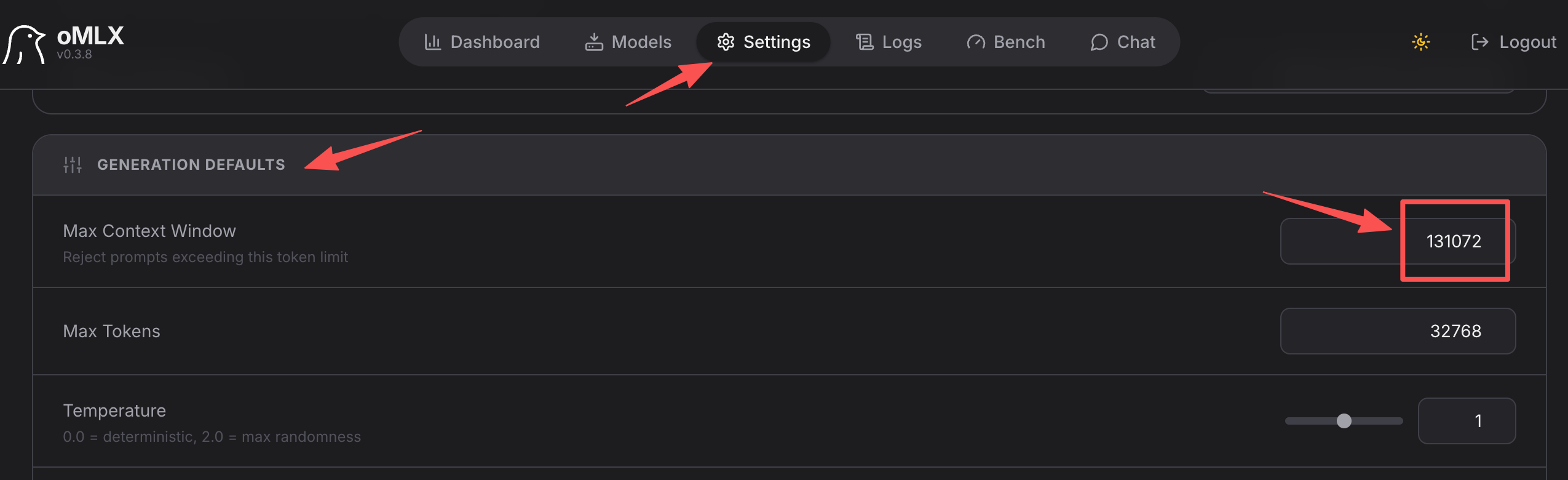
如果你维护的是 oMLX 配置文件,请把对应模型的 max_context_window 设置为同样的 token 数。不同版本的配置文件路径和热更新行为可能不同,优先以当前版本 Dashboard 展示和导出的配置为准。配置后建议重启 oMLX 服务,再验证 /v1/models 和一次短请求。
注意:
max_context_window是推理框架允许的上下文窗口- OpenAI 请求体里的
max_tokens只是单次生成上限,不是上下文窗口 - SSD KV cache 是缓存和复用机制,不等于模型训练支持的最大上下文
- 如果模型本身不支持目标上下文长度,上下文设置再大也不可靠
验证 oMLX 服务
查看模型列表:
curl http://127.0.0.1:8000/v1/models做一次非流式推理。model 使用 /v1/models 里看到的实际模型 ID 或 alias:
curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ --data-raw '{ "model": "Qwen3.6-35B-A3B-4bit", "messages": [ { "role": "user", "content": "用一句中文回复:oMLX 服务可用。" } ], "max_tokens": 64, "temperature": 0.2 }'如果你启用了 oMLX API Key,在请求里增加:
-H "Authorization: Bearer <OMLX_API_KEY>"启动 Provider Agent
oMLX 服务可用后,先跑预检:
./token-provider-agent preflight start \ --model qwen3.6:35b \ --base-url http://127.0.0.1:8000 \ --api-format omlx \ --runtime-model-id Qwen3.6-35B-A3B-4bit预检通过后正式启动:
./token-provider-agent start \ --api-key stp-... \ --model qwen3.6:35b \ --base-url http://127.0.0.1:8000 \ --api-format omlx \ --runtime-model-id Qwen3.6-35B-A3B-4bit如果 oMLX 启用了推理框架 API Key,同时传入:
--runtime-api-key <OMLX_API_KEY>